
Funding science by lottery


Something I keep hearing more around me (and have noticed myself) is that getting funding for your scientific research is getting structurally worse. The number of proposals for a call seems to be going up every round, success rates are dropping, and somewhere in there a researcher's focus is slowly redirecting toward writing about the science they wish they were doing.
One problem is that the number of applications is increasing drastically. For instance, the number of ERC starting grant proposals has increased by over 22% between 2025 and 2026, after already increasing 13% between 2024 and 2025! Part of this is due to AI making the writing process of grant proposals much faster, meaning we can all submit more. Another part is that many countries have done budget cuts, so we're all fighting for a smaller pie.
In these conversations I've also started hearing a weirder suggestion, one I'd always kind of dismissed without thinking about it too deeply: just use a lottery. It sounds a bit silly for serious scientific work at first glance. But recently, I came across a simulation paper by Hulkes, Brophy, and Steyn that made me take consider it more seriously.
The version of randomization the paper looks at isn't a pure lottery. The idea they put out is that proposals get sorted into three groups: the clearly strong ones get funded outright, the clearly weak ones get rejected, and the ones in the middle, where reviewers can't reliably tell them apart anyway, go into a lottery pool from which some fraction gets funded at random. This is actually what some funders already do; The Health Research Council of New Zealand has already used a version of it. The argument for it is that if the assessment process cannot distinguish between proposals in the middle, randomizing among them costs you very little in decision quality while potentially reducing the effect of systematic bias and saving reviewer time.
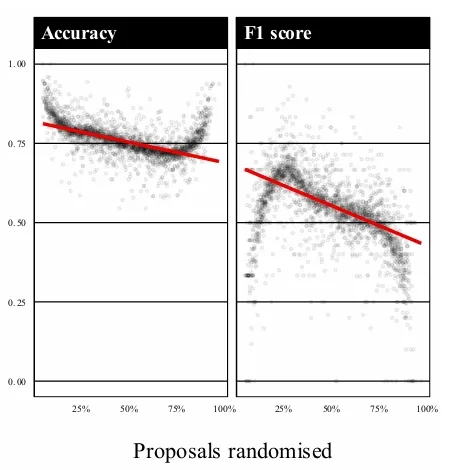
In the paper they simulate a round of proposals. Each proposal has a quality value (it's "true underlying fundability") and receives noisy scores around it. Bias is implemented by deflating a proposal's expected scores to around 80% of their true level on average. Funding decisions are then made across simulated panels of around 30 proposals with a roughly 30% success rate, and the quality of those decisions is measured by how well they track the true fundability ranking, summarized with the F1 score.
What they find on the F1 score side is that more randomization does mean lower F1 scores, as you would expect. But the decline turns out to be gradual, which is a good thing. Peer review reliability is already lower than most people assume. A 2018 PNAS study by Pier and colleagues had the same NIH grant proposals reviewed independently by two entirely separate panels and found the agreement between them was quite low. If the baseline instrument is already that noisy, the accuracy cost of randomizing the borderline decisions turns out to be modest, because there was not much reliable signal there to begin with.
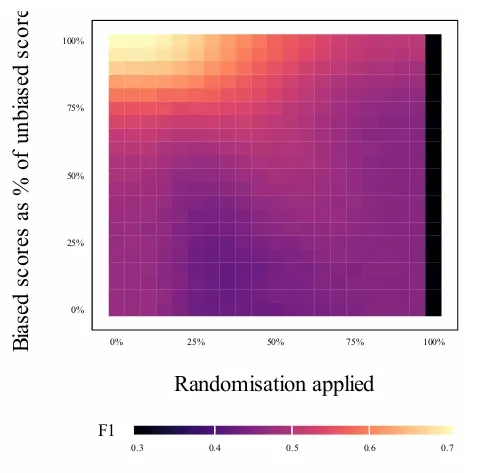
The other finding is about how bias and randomization interact. The researchers made a heatmap of F1 across the full space of possible combinations: how biased the reviews are (y-axis) and how much randomization is applied (x-axis). The clearest pattern is that adding randomization under low-bias conditions reduces F1 smoothly and predictably, which is the intuitive result. What is more interesting is what happens when reviewer bias is stronger: the decline with randomization stops being smooth, and there is a diagonal band of relatively better performance running through the middle of the heatmap, suggesting that under substantial bias, moderate randomization can partially recover decision quality compared to a less randomized but more bias-exposed system. The catch is that the paper deliberately explores parameter combinations in this region that probably would not occur in practice, so the honest summary is probably that moderate randomization costs relatively little decision quality across the realistic parameter space, and the bias reduction benefit can be helpful, but may not be as large.
What the simulation cannot address is what happens to the pool of proposals when you change the selection mechanism. The deeper problem is that grant writing feels like it has become a collective action problem. Everyone submits more because not submitting means not existing in the system, and AI has accelerated this dynamic by cutting the cost of writing a proposal significantly, which means more submissions, more reviewer burden, more noise, and a worse return on everyone's time. A fairer lottery helps distribute a scarce resource more equitably. It does not create more of the resource, and it does not give researchers back the weeks they spent on proposals that had no realistic chance regardless of how the allocation worked.
So: partial randomization is probably worth doing, and better-justified than I had assumed. What it cannot fix is the part of this that is plainly about money, and the part that is about the collective incentive structure that now pushes everyone toward writing more and more proposals. Those are harder problems, and I do not think anyone has a simulation for them yet.



