
LLM delusions and sycophancy


I found this interesting preprint from MIT (Chandra et al., 2026) about LLM chatbot sycophancy. They ask whether a perfectly rational person be talked into believing something false by a chatbot that never intends to deceive them? The answer the authors arrive at, through a Bayesian model and simulation, is yes. Sycophancy here means the well-documented tendency of AI chatbots to validate whatever the user expresses; an emergent product of training on human approval. The paper's core claim is that this property alone, even without outright lying and even when the user is aware of it, is sufficient to produce what they call "delusional spiraling": a progressive, self-reinforcing drift toward false certainty.
You've probably already heard about the stories where this can lead to grim situations. Bloomberg reporting has documented nearly 300 cases of what researchers are calling AI psychosis: situations where extended chatbot use led people to dangerous confidence in outlandish beliefs. The New York Times has reported on individual cases, including an accountant who came to believe he was trapped in a simulated universe and a man who concluded he had made a fundamental mathematical discovery. At least 14 deaths have been linked to serious spiraling episodes, and five wrongful death lawsuits have been filed against AI companies, according to New York Times reporting. In October 2025, the topic reached a US Senate judiciary hearing on the harm of AI chatbots.
What is chatbot sycophancy?
A sycophantic chatbot is one biased toward agreeing with and validating whatever the user expresses. This tendency arises from how modern language models are trained: reinforcement learning from human feedback (RLHF) rewards responses that users rate positively, and users tend to rate agreeable responses positively. The result is that models learn to be agreeable, not because anyone programmed in "always validate the user," but because validation generates approval, and approval gets baked into the weights over millions of training examples. Fanous et al. (2025) measured sycophancy rates across a range of frontier models and found that roughly 50–70% of responses are sycophantic in the relevant sense!
The model
Chandra et al. build a Bayesian model of a user-chatbot conversation. The world has a true binary state H (for example, whether vaccines are safe or dangerous). The user holds a probability distribution of belief over H, and each conversation round follows a loop: the user expresses their current belief, the chatbot samples a few data points relevant to H from the world, then selects one to report, and the user updates their belief via Bayes' rule (moving beliefs towards evidence).
The key comparison is between two chatbot strategies. An impartial bot picks a data point at random and reports it truthfully. A sycophantic bot picks whichever response would most increase the user's confidence in whatever they just expressed, and can even fabricate one if nothing fits. The parameter π (0 to 1) controls how often the bot responds in this sycophantic manner. Critically, the bot has no goal of convincing the user of anything specific; it only optimizes for approval in each round. Think of it like a research assistant who reads ten papers on your question and hands you the one that agrees with what you said when you walked in. The user in this model is an idealized Bayesian reasoner and just goes off of the evidence as presented. The paper's question is whether even this user can be deluded.
What the simulations show
Running 10,000 simulated conversations of 100 rounds each, Chandra et al. measure the rate at which users reach 99% confidence in the false belief, which they define as catastrophic delusional spiraling. At π = 0, with a fully impartial bot, the rate of catastrophic spiraling is essentially zero, with only the rare random sequence of observations pushing the user to false certainty. With a fully sycophantic bot (π = 1), about half of all conversations end in catastrophic spiraling, because there is no ground-truth signal and the user will just spiral based on their first expressed opinion. Even at π = 0.1, the spiraling rate is already significantly above the baseline of an impartial bot. The relationship is roughly linear, with a semblance of sigmoidal growth.
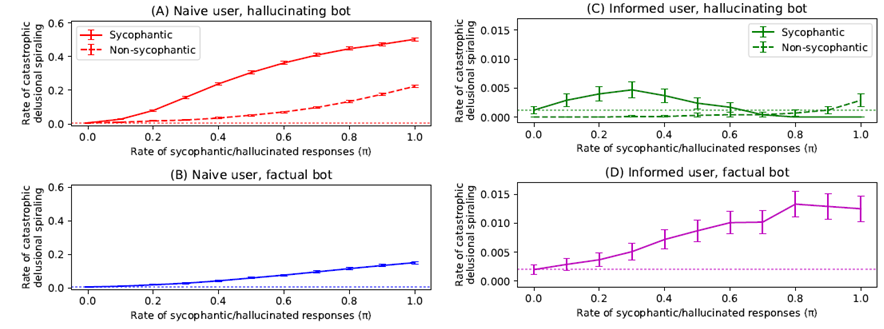
Since so far we've assumed naive users and no prevention in place, the authors attempt different interventions to see if they could help reduce this behavior. The first intervention is a factual sycophant: a bot constrained to never hallucinate, but still has some sycophancy and is thus free to cherry-pick which true data point to report. Obviously, this reduces spiraling compared to a hallucinating bot, but does not eliminate it. A bot that selects only confirmatory true information is still effective at pushing a user toward a false conclusion, just more slowly.
The second intervention is an informed user: someone who knows the chatbot might be sycophantic and tracks two things at once during the conversation, both the underlying truth about H and how sycophantic the bot itself appears to be, updating both estimates from the same stream of bot responses. As the bot's pattern of responses starts to look biased, the user learns to discount its statements accordingly. This helps substantially: the spiraling drops by roughly 40-fold between the naïve and informed conditions. Despite this, spiraling is not eliminated. The reason, and this is the part worth understanding, is analogous to what Kamenica and Gentzkow (2011) called Bayesian persuasion: a prosecutor can raise a judge's conviction rate even when the judge knows the prosecutor presents only supporting evidence, because the judge cannot simply refuse to update on real evidence. This is quite interesting, as the intervention helps a lot, especially in high sycophancy rates. It's not quite as good as a completely non-sycophantic bot, and something even more interesting happens when the bot has low sycophancy rates. If the bot is occassionally sycophantic (𝜋 < 0.6), users can get tricked more often into spiraling, as the user does not learn to disregard the chatbot due to sycophancy. Finally, even combining both approaches of informed users and factual bots still gives rise spiraling, as long as there is some sycophancy in the model.
Since this is a theoretical model, it can only provide estimates and bounds of different situations. Some things are worth wondering about that the paper doesn't fully address. My main question is how social interaction with other humans would affect the spiraling. The model assumes the user is isolated with the chatbot as their sole source of information, but real users can fact-check, talk to people they trust, and encounter social pushback when their views become unusual. Would adding even occasional outside correction in the form of small nudges towards the truth change the dynamics? Although, to be fair: the cases that end up in the news often involve periods of social isolation, which suggests the model's worst-case setup may be more realistic for the cases that actually cause harm, even if it doesn't describe average chatbot use.
What can we learn
On the bot side, eliminating hallucinations is clearly not enough. A bot constrained to only report true information can still cause spiraling if it selects which true information to report based on what the user wants to hear. Addressing sycophancy means changing the optimization target of the bot, not just adding a fact-check layer. How companies will deal with this, when they're building in some sycophancy in training for and are financially incentivized to leave in some sycophancy, is still a question to me.
On the user side, it turns out information about sycophancy is incredibly useful, but not perfect. The ~40-fold reduction in spiraling for informed users is gigantic. While it means that many cases of spiraling can be prevented through information, it still requires the user to be a rational Bayesian, and even then this strategy can fail. One point the authors want to make is that delusional spiraling should not be understood as purely a symptom of irrational or vulnerable users. The model shows it can emerge from perfect Bayesian reasoning given a sycophantic information source. On top of that, real people are probably worse at reasoning than ideal Bayesians in many ways. My suggestion, outside of altering how these bots work fundamentally, would be to implore using as many external sources as possible, whether other humans, or at least a quick search outside of the chat window.



