Playing against a board game L'Oaf AI


I wrote about making a L'Oaf AI and learning strategies from it a week or so ago. In the article I mentioned letting readers play against the AI, and after getting permission from the game's designer, Bart de Jong, I was able to put something together where you can play against the AI. Before finishing this, I added a risky-AI mode (one that tries to win instead of drawing when things get hard), fixed a minor mistake I had in my previous code, and re-ran the analysis code. Scroll down to the bottom of the post if you immediately want to try playing against the bot.
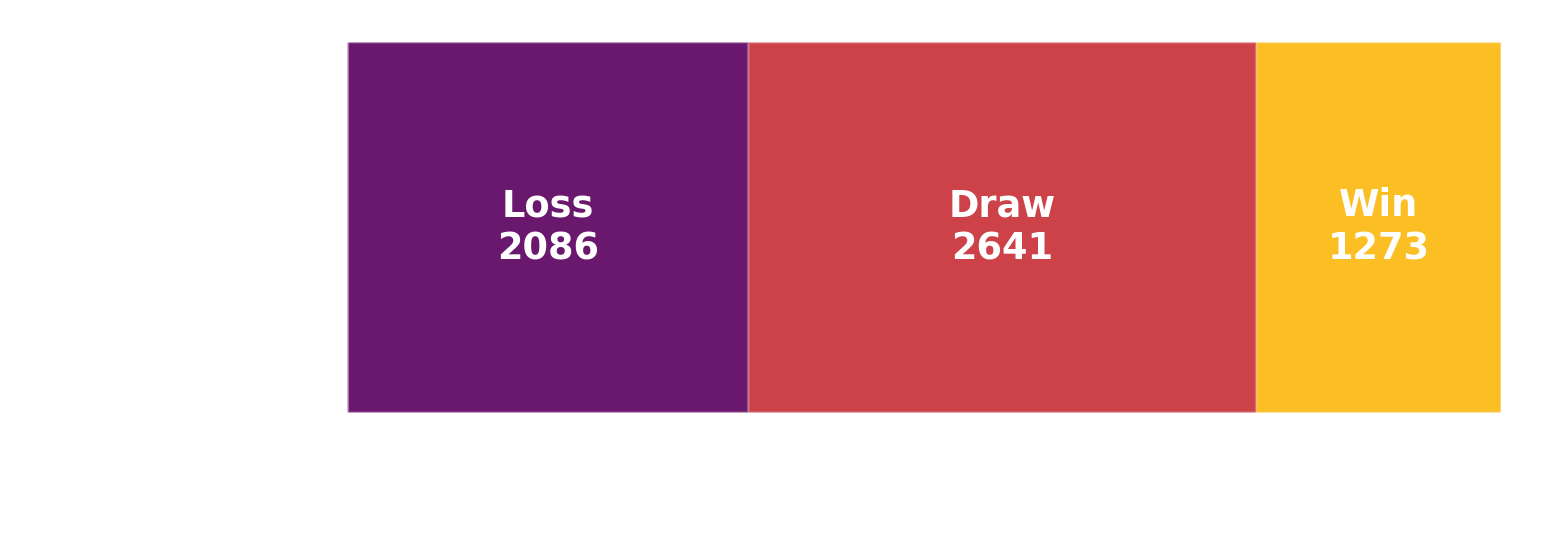
Let me know if you end up winning in a comment. I don't think I ever won, but I was able to find a strategy to reliably draw against the normal bot. We should be able to win some of the times, as even the random playstyle could eek out a few wins here and there.